Asynchronous Job streams
In the Connector Builder UI, you can create two types of streams: Synchronous Request and Asynchronous Job. Understanding the difference is important for efficiently extracting data from APIs that use asynchronous processing.
Synchronous Streams
Synchronous streams operate in real-time, where:
- The connector makes a request to an API endpoint
- The API responds immediately with data
- The connector processes and returns that data in the same operation
This is the simpler, more common pattern used for most APIs that can return data immediately.
Asynchronous Streams
Asynchronous streams handle scenarios where data extraction happens over multiple steps:
- Creation: You request a job to be created (like a report generation)
- Polling: You periodically check if the job is complete
- Download: Once the job is complete, you download the results
This approach is necessary for APIs that handle large datasets or resource-intensive operations that cannot be completed in a single request-response cycle.
When to Use Asynchronous Streams
Use asynchronous streams when:
- The API requires you to trigger a job and wait for it to complete
- You're working with large datasets that need server-side processing
- The API documentation mentions job creation, status checking, and result download
- Data generation takes too long to be handled in a single request
Common examples include analytics report generation, large data exports (like SendGrid contacts), complex data processing operations, and batch-processed operations.
Configuring an Asynchronous Stream
To make an existing stream asynchronous, use the Retrieval Type selector at the top-right of the stream configuration and select Asynchronous Job.
To create a new stream as an asynchronous stream, click the + add stream button, and select Retrieval Type > Asynchronous Job.
An asynchronous stream in the Connector Builder UI is divided into four main tabs: Creation, Polling, Download, and Schema. The first three tabs correspond to the three phases of asynchronous data extraction, while the Schema tab allows you to configure the stream's data schema.
Creation Tab
The Creation tab configures how to request that a job be created on the server.
Key Components:
- API Endpoint URL (required): The full URL that the request should be sent to create the job
- HTTP Method: The HTTP method for job creation, typically POST but can vary by API
- HTTP Response Format: Format of the response from the job creation request, which will also be used for polling responses
- Authenticator: Authentication method for the creation request, with support for various authentication types
- Query Parameters: Query parameters to include in the creation request
- Request Headers: HTTP headers to include in the creation request
- Request Body: Request body content for the creation request
- Incremental Sync: Configuration for incremental synchronization if the stream supports it
- Partition Router: Configuration for partitioning the stream into multiple requests
- Error Handler: Error handling configuration for creation requests
Additional configuration options are available in the collapsed "Advanced" section for less common use cases.
Example Configuration (SendGrid):
In the UI, for the SendGrid contacts export, you would configure:
- API Endpoint URL field:
https://api.sendgrid.com/v3/marketing/contacts/exports - HTTP Method dropdown:
POST - HTTP Response Format dropdown:
JSON - In the Authentication section:
- Select Bearer Token authentication type
- Fill out the API Key user input with your SendGrid API key
Polling Tab
The Polling tab defines how to check the status of a running job.
Key Components:
- API Endpoint URL (required): The full URL for checking job status. Use the
{{ creation_response }}variable to reference the creation request response when constructing this URL - HTTP Method: HTTP method for status checking, typically GET but can vary by API
- Authenticator: Authentication method for polling requests
- Status Extractor: Extracts the job status value from the polling response using a field path
- Status Mapping: Maps API-specific status values to standard connector statuses (completed, failed, running, timeout)
- Download Target Extractor: Extracts the URL or identifier for downloading results from the polling response
- Polling Job Timeout: Maximum time to wait for job completion before timing out
- Query Parameters: Query parameters for polling requests
- Request Headers: HTTP headers for polling requests
- Request Body: Request body for polling requests
- Error Handler: Error handling configuration for polling requests
Status Extractor and Status Mapping Explained
The Status Extractor and Status Mapping work together:
-
Status Extractor defines a path to extract the status value from the API response. It uses a field path to point into the JSON response to find the status value.
-
Status Mapping maps the extracted status values to standard connector statuses:
- Completed: Job finished successfully and data is ready for download
- Failed: Job encountered an error and cannot be completed
- Running: Job is still processing, need to keep polling
- Timeout: Job took too long to complete, should be aborted
For each of these, you should put all of the possible status values that the API might return which indicate that the job is in that state.
The connector first uses the Status Extractor to get the raw status value, then uses the Status Mapping to determine what action to take next.
Download Target Extractor and Download Target Requester Explained
The Download Target Extractor works similarly to the Status Extractor but extracts a download URL or identifier from the successful API response during the Polling stage. This extracted value will be used in the Download stage to retrieve the data.
The Download Target Requester (Optional) makes an additional API request once jobs have completed to retrieve download URLs or identifiers. When configured, the Download Target Extractor will operate on this API response rather than the API response from the Polling stage. This is typically only needed for complex APIs.
The Download Target Extractor is optional if not using the Download Target Requester. If not specified, the connector will make a single request during the Download stage without the download_target interpolation context. This is suitable for simple APIs.
Example Configuration (SendGrid)
In the UI, for the SendGrid contacts export, you would configure:
- URL field:
https://api.sendgrid.com/v3/marketing/contacts/exports/{{creation_response['id']}} - HTTP Method dropdown:
GET - In the Status Extractor section:
- Set the Field Path to:
status
- Set the Field Path to:
- In the Status Mapping section:
- Set Completed to:
ready - Set Failed to:
failed - Set Running to:
pending - Set Timeout to:
timeout
- Set Completed to:
- In the Download Target Extractor section:
- Set the Field Path to:
urls
- Set the Field Path to:
- Polling Job Timeout: Set an appropriate timeout value (e.g.,
30for 30 minutes)
Download Tab
The Download tab configures how to retrieve the results once the job is complete. This tab provides comprehensive configuration options for processing the downloaded data.
Key Components
- API Endpoint URL (required): The full URL for downloading results. Use the
{{ download_target }}variable to reference the value extracted by the Download Target Extractor. Use the{{ creation_response }}variable to reference the creation request response when constructing this URL and use the{{ polling_response }}to reference the polling response when constructing the download URL. - HTTP Method: HTTP method for downloading, typically GET but can vary by API
- Download HTTP Response Format: Format of the downloaded data (JSON, CSV, XML, etc.)
- Record Selector: Configuration for identifying and extracting individual records from the response, including the extractor field path
- Primary Key: Unique identifier field(s) for records in the stream
- Authenticator: Authentication method for download requests
- Query Parameters: Query parameters for download requests
- Request Headers: HTTP headers for download requests
- Request Body: Request body for download requests
- Download Paginator: Pagination configuration if the download response is paginated
- Transformations: Data transformation rules to apply to downloaded records
- Error Handler: Error handling configuration for download requests
Example Configuration (SendGrid):
In the UI, for the SendGrid contacts export, you would configure:
- URL field:
{{ download_target }} - HTTP Method dropdown:
GET - HTTP Response Format dropdown:
CSV - In the Record Selector section:
- Leave the Field Path empty since we want to use the entire CSV content
- Set Primary Key to:
CONTACT_ID
Testing Asynchronous Streams in the UI
Click the "Test" button in the top right corner of the Connector Builder UI to test your connector.
Asynchronous streams can take longer to test than synchronous streams, so be patient. However, you can use the Cancel button to stop the test at any time.
After the test completes, you'll see several important panels that help you understand what's happening during the asynchronous process:
Main Records / Request / Response Tabs
The main Records / Request / Response tabs in the testing panel show the final download phase of your asynchronous stream:
-
Records Tab: Shows the records that were created from the final download response.
-
Request Tab: Shows the HTTP request sent to download the final data, including the download URL, headers, and any request parameters.
-
Response Tab: Shows the actual data returned from the API, which is used to produce the records you're trying to sync.
For the SendGrid example, the main Request tab would show a GET request to the URL extracted from the polling response, and the Response tab would show the CSV data containing the contacts.
Other Requests Panel
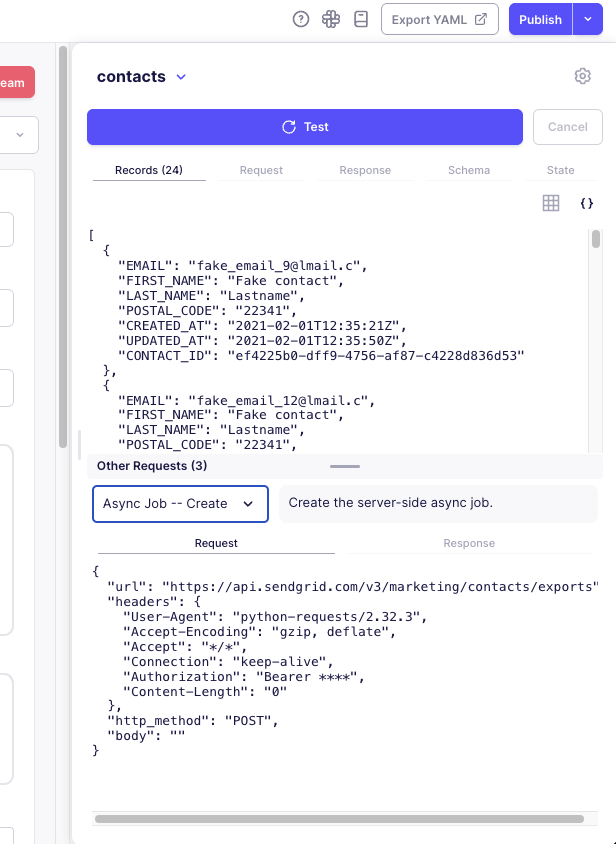
The Other Requests panel can be helpful for debugging asynchronous streams. This panel shows the intermediate requests and responses that occurred during the asynchronous process:
-
Creation Requests: Shows the request sent to create the job and the API's response, including any job ID or token returned.
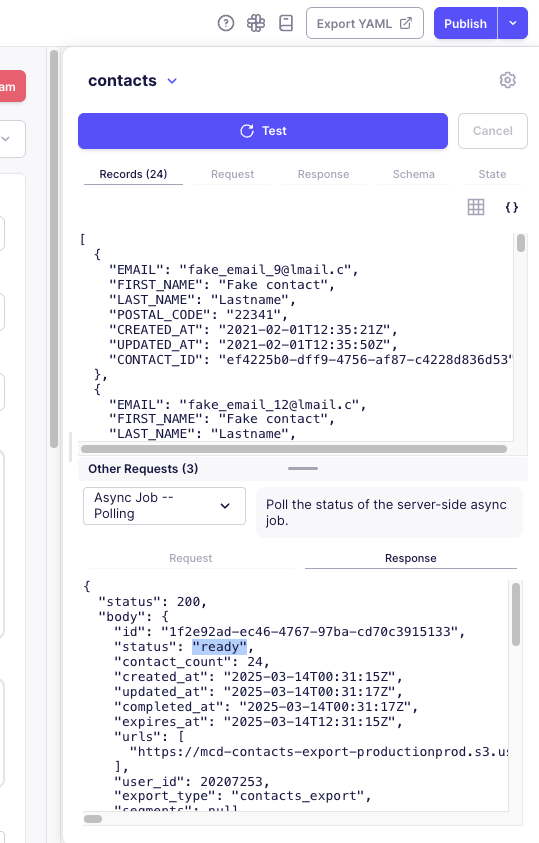
-
Polling Requests: Shows each polling request sent to check the job status and the API's response, including the status values returned.
To view the details of the creation and polling stages:
- After running a test, look for the "Other Requests" panel at the bottom of the screen
- Select a request from the dropdown menu (they are typically labeled like "Async Job -- Create" or "Async Job -- Polling")
- Use the tabs to switch between the request and response details
- Request tab: The request URL, method, headers, and body
- Response tab: The response status, headers, and body
How Asynchronous Data Extraction Works
Let's walk through the complete flow using the SendGrid contacts export example:
-
Job Creation:
- The connector sends a POST request to the exports endpoint with the user's API key
- SendGrid begins generating the export and returns a response with a job ID
- In the Other Requests panel, you'll see this creation request and its response
-
Status Checking:
- The connector uses the job ID to construct the polling URL
- It periodically sends GET requests to this URL to check the status
- SendGrid returns updates about the job status
- In the Other Requests panel, you'll see these polling requests and responses
-
Status Evaluation:
- The connector extracts the status value (e.g., "pending") using the Status Extractor
- It maps this to a standard status (e.g., "running") using the Status Mapping
- It continues polling until the status changes to "ready" (mapped to "completed")
-
Download URL Extraction:
- When the job is complete, the connector extracts the download URL using the Download Target Extractor
- In the Other Requests panel, you'll see the final polling response that contains this URL
-
Result Download:
- The connector sends a GET request to the extracted URL
- SendGrid returns a CSV file with the contacts data
- In the main Request/Response tabs, you'll see this download request and the resulting data
Best Practices for Asynchronous Streams
-
Verify Each Stage: Use the Other Requests panel to verify that each stage is working correctly:
- Confirm the job creation request is successful
- Verify that status is at the expected place with the expected values in the polling response
- Ensure the download target is correctly extracted by checking the main Request tab URL
-
Configure Status Mapping Properly: Include all possible API status values in your status mapping.
-
Use the Right HTTP Response Format: Make sure you select the correct HTTP Response Format (JSON, CSV, XML, etc.) for both creation and download phases.
-
Configure Appropriate Timeouts: Set reasonable values for
polling_job_timeoutto avoid indefinite waiting for job completion. -
Handle Rate Limits: Many APIs limit how frequently you can poll for job status. Configure appropriate error handling and retry strategies.
-
Test Thoroughly: Test the stream verify each phase of the asynchronous process works correctly.
-
Leverage Enhanced Interpolation: Take advantage of
creation_responseandpolling_responsecontexts to simplify your configuration. For APIs that provide download URLs directly in creation or polling responses, you may not need a Download Target Extractor at all.
Remember that asynchronous streams often take longer to test than synchronous streams, especially if the API takes time to process jobs.