Refreshing your data
A Refresh Sync erases the current cursor you have set for any incremental streams, effectively ‘rewinding’ the sync back to the beginning. This is helpful in the following scenarios:
- The source you're syncing from does not sync record deletions/removals, and you wish to mirror the source stream, which would include removing deleted records
- The source you are syncing from is unreliable and you wish to re-attempt the sync
- Something has gone wrong with your sync, and you wish to try again
Refresh Syncs do not create data downtime. While the Refresh Sync is running, the previous data in your destination remains available to query. Only at the successful conclusion of a Refresh Sync will the newly refreshed data be swapped or merged into place. This is an improvement from the previous Reset Syncs that Airbyte had in earlier iterations.
When performing a Refresh Sync, any records you’ve already imported will be imported again for the stream(s) being refreshed (assuming they are still present within the source), leading to a slower and more expensive sync than you might be used to. Refresh Syncs will block any scheduled syncs from occurring until they are complete. During a Refresh Sync, the streams that are not being refreshed will also sync normally in order to lower data latency . All Refresh Syncs are resumable if the underlying source and destination support checkpointing.
Depending on the sync mode you’ve selected, you’ll be able to choose between the following refresh options:
| Stream Sync Mode | Refresh stream and remove records | Refresh stream and retain records | Clear |
|---|---|---|---|
| Incremental | Append + Dedupe | Available | Available | Available |
| Full Refresh | Overwrite | Not available | Not available | Available |
| Full Refresh | Append | Not available | Not available | Available |
| Incremental | Append | Not available | Available | Available |
For supported destinations, and depending on the sync mode you have selected, there are two types of refreshes - "retaining history" and "removing history". Both kinds of Refresh Syncs can be triggered from the UI and via the Airbyte API at either the stream or connection levels (although both might not be available depending on your sync mode).
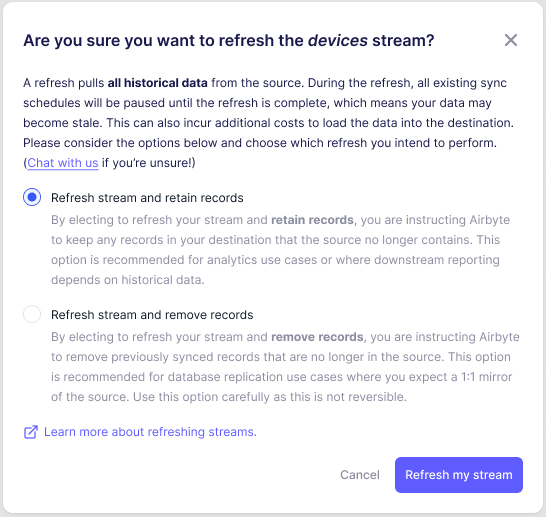
Refresh and Remove Records
Refresh and Remove Records Syncs will only display data in the destination’s final tables that was newly synced since the refresh was initiated. This is the simplest type of Refresh Sync.
Not all sources keep their history forever. If you perform a Refresh and Remove Records Sync, and your source does not retain all of its records, this may lead to data loss. If you need to keep all history, then we recommend using Refresh and Retain Records. If that is not an option, then you should back up the data in your destination before running the Refresh and Remove Records.
Refresh and Retain Records
Refresh and Retain Records Syncs keep the records you had previously, and merge in the new data from this sync onward with the data previously stored in your destination. Using a Refresh and Retain Records Sync with a Deduplicated Sync mode is the best way to recover from an unreliable (e.g. lossy or buggy) source.
Refresh and Retain Records Syncs will lead to increased data storage in your destination (as the old and new copies of your data are both stored). This may also lead to increased compute costs and slower syncs, depending on your destination.
Data Generations
With the advent of Refresh and Retain History Syncs, Airbyte has provided a way for you to determine if any given record is from before or after the refresh took place. This is helpful when disambiguating historic data which may have changed due to an unreliable source. We call this information the “Generation” of the data, indicated by the _airbyte_generation_id column. Every time a Refresh Sync (of either type) occurs, the generation increases. _airbyte_generation_id is a monotonically increasing counter which maps to this notion of “generation” of data. Data which was synced before the addition of this feature will have a generation of null.
Example: Understanding and Recovering from a Flaky Source
Consider the following example. You are extracting data into your data warehouse and notice that data for March, 2024 is missing. You are using an append sync mode.
| year_month (pk) | total_sales | _airbyte_extracted_at | _airbyte_generation_id | _airbyte_meta | _airbyte_raw_id |
|---|---|---|---|---|---|
| 2024-01 | $100 | 2024-01-01 12:00:00 | 0 | { changes: [], sync_id: 1, } | aaa-aaa |
| 2024-02 | $200 | 2024-01-01 12:00:00 | 0 | { changes: [], sync_id: 1, } | bbb-bbb |
| 2024-04 | $400 | 2024-01-01 12:00:00 | 0 | { changes: [], sync_id: 1, } | ccc-ccc |
You decide to do a Refresh and Retain History Sync, and now have the missing row
| year_month (pk) | total_sales | _airbyte_extracted_at | _airbyte_generation_id | _airbyte_meta | _airbyte_raw_id |
|---|---|---|---|---|---|
| 2024-01 | $100 | 2024-01-01 12:00:00 | 0 | { changes: [], sync_id: 1, } | aaa-aaa |
| 2024-02 | $300 | 2024-01-01 12:00:00 | 0 | { changes: [], sync_id: 1, } | bbb-bbb |
| 2024-04 | $400 | 2024-01-01 12:00:00 | 0 | { changes: [], sync_id: 1, } | ccc-ccc |
| 2024-01 | $100 | 2024-01-02 12:00:00 | 1 | { changes: [], sync_id: 2, } | ddd-ddd |
| 2024-02 | $200 | 2024-01-02 12:00:00 | 1 | { changes: [], sync_id: 2, } | eee-eee |
| 2024-03 | $300 | 2024-01-02 12:00:00 | 1 | { changes: [], sync_id: 2, } | fff-fff |
| 2024-04 | $400 | 2024-01-02 12:00:00 | 1 | { changes: [], sync_id: 2, } | ggg-ggg |
It is now possible to compute the different total values of sum(total_sales) for each generation, and then if they are different, to look for records which didn’t exist before and after the reset, in different generations. If you aren’t using an append sync mode, the data for both the previous and current generations will be retained in your destination’s raw tables, but not displayed in the final tables. A similar analysis could be performed looking for records which exist in the current generations, but not the previous.
Example: Discovering Deletes from a Source that Hides Them.
Another example of using generation Id: You are extracting data into your data warehouse from a source which doesn’t track deletes. You are using an append+dedupe sync mode, and you want to detect when a record has been deleted from the source:
| user_id (pk) | name | _airbyte_extracted_at | _airbyte_generation_id | _airbyte_meta | _airbyte_raw_id |
|---|---|---|---|---|---|
| 1 | Evan | 2024-01-01 12:00:00 | 0 | { changes: [], sync_id: 1, } | aaa-aaa |
| 2 | Davin | 2024-01-01 12:00:00 | 0 | { changes: [], sync_id: 1, } | bbb-bbb |
| 3 | Benoit | 2024-01-01 12:00:00 | 0 | { changes: [], sync_id: 1, } | ccc-ccc |
Time passes, and you opt to do a Refresh and Remove History Sync to see if any user was removed in the source. Your final table now looks like:
| user_id (pk) | name | _airbyte_extracted_at | _airbyte_generation_id | _airbyte_meta | _airbyte_raw_id |
|---|---|---|---|---|---|
| 1 | Evan | 2024-02-02 12:00:00 | 1 | { changes: [], sync_id: 2, } | ddd-ddd |
| 2 | Davin | 2024-01-01 12:00:00 | 0 | { changes: [], sync_id: 1, } | bbb-bbb |
| 3 | Benoit | 2024-02-02 12:00:00 | 1 | { changes: [], sync_id: 2, } | eee-eee |
Notice that user #2’s latest entry doesn’t belong to the current (e.g. max(_airbyte_generation_id)) generation. This informs you that the source no longer includes a record for this primary key, and it has been deleted. In your downstream tables or analysis, you can opt to exclude this record.
Frequently Asked Questions (FAQ)
How is a Full Refresh sync that uses Append + Overwrite to write to the destination different from a refresh?
They're completely identical! A Full Refresh | Append + Overwite sync is running a refresh on every sync and retaining all records. A Full Refresh | Overwrite sync is running a refresh on every sync and removing any reecords that no longer appear in the source. Notably, this means that _airbyte_generation_id will increment on every sync.
Does the generation ID reset to 0 after running a Clear and sync again?
The generation ID will be incremented whenever you run a clear or refresh. Airbyte will never decrease the generation ID.
Iif you run a Refresh immediately after running a Clear (including syncing a full refresh stream normally, as noted in the above question, that will also increment the generation ID. This means the generation ID will increment twice, even though one of those "generations" never emitted any records.
For DV2 destinations, how do clears or Refreshes that remove records interact with the raw and final tables?
All pre-existing data will be deleted from both the raw and final tables. If you want to retain that data, you should run a Refresh that retains records.
If I Refresh or Clear a single stream in a connection, does the generation ID increment for other streams in that connection?
No. Streams within a connection have independent generation IDs. Clearing/Refreshing a single stream will only increment that stream's generation. Other streams are unaffected.