Azure Blob Storage
This page contains the setup guide and reference information for the Azure Blob Storage source connector.
Cloud storage may incur egress costs. Egress refers to data that is transferred out of the cloud storage system, such as when you download files or access them from a different location. For more information, see the Azure Blob Storage pricing guide.
Prerequisites
- Tenant ID of the Microsoft Azure Application user
- Azure Blob Storage account name
- Azure blob storage container (Bucket) Name
Minimum permissions (role Storage Blob Data Reader ):
[
{
"actions": [
"Microsoft.Storage/storageAccounts/blobServices/containers/read",
"Microsoft.Storage/storageAccounts/blobServices/generateUserDelegationKey/action"
],
"notActions": [],
"dataActions": [
"Microsoft.Storage/storageAccounts/blobServices/containers/blobs/read"
],
"notDataActions": []
}
]
Setup guide
Step 1: Set up Azure Blob Storage
- Create a storage account and grant roles details
To use Oauth2 or Client Credentials Authentication methods, Access Control (IAM) should be setup.
It is recommended
to use role Storage Blob Data Reader Follow these steps to set up an IAM role:
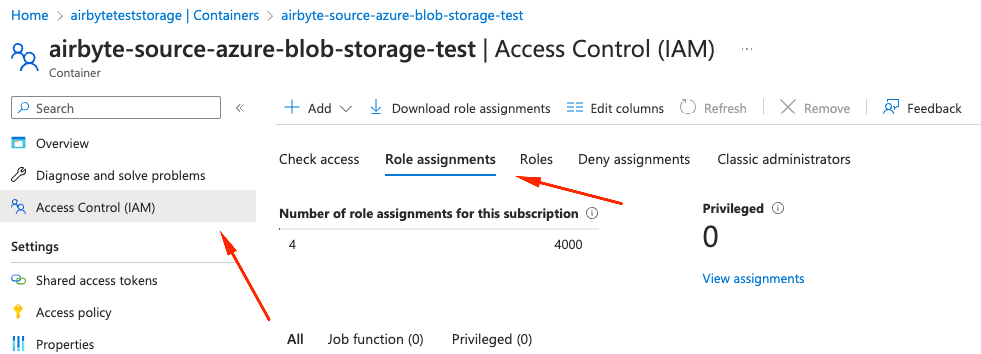
Add and select Add role assignment from the dropdown list 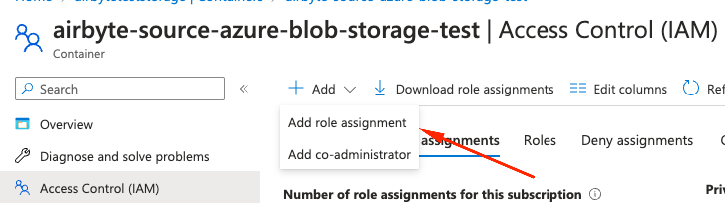
Storage Blob Data Reader in search box, Select role from the list and click Next 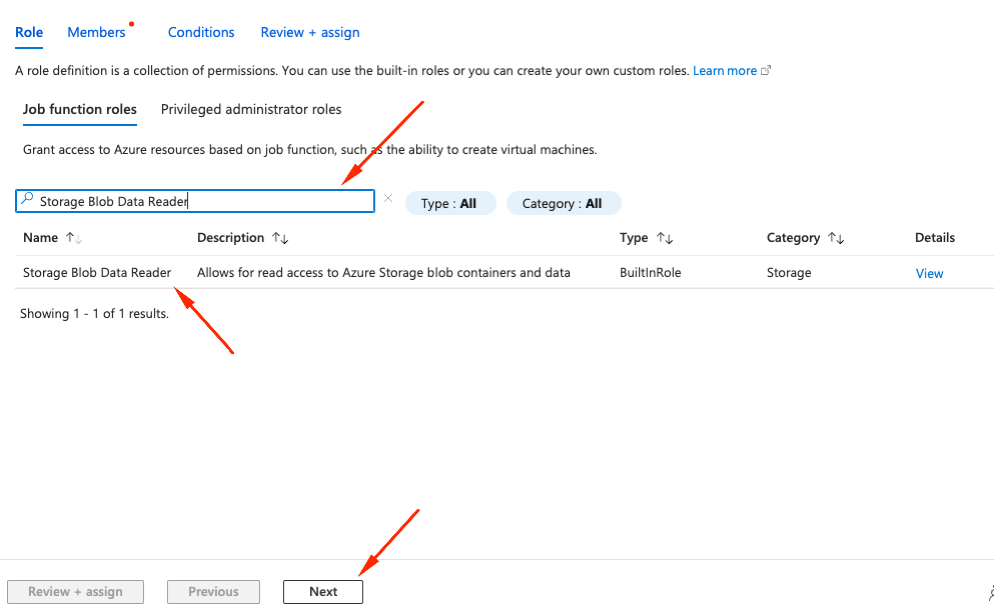
User, Group, or service principal, click on members and select member(s) so they appear in table and click Next 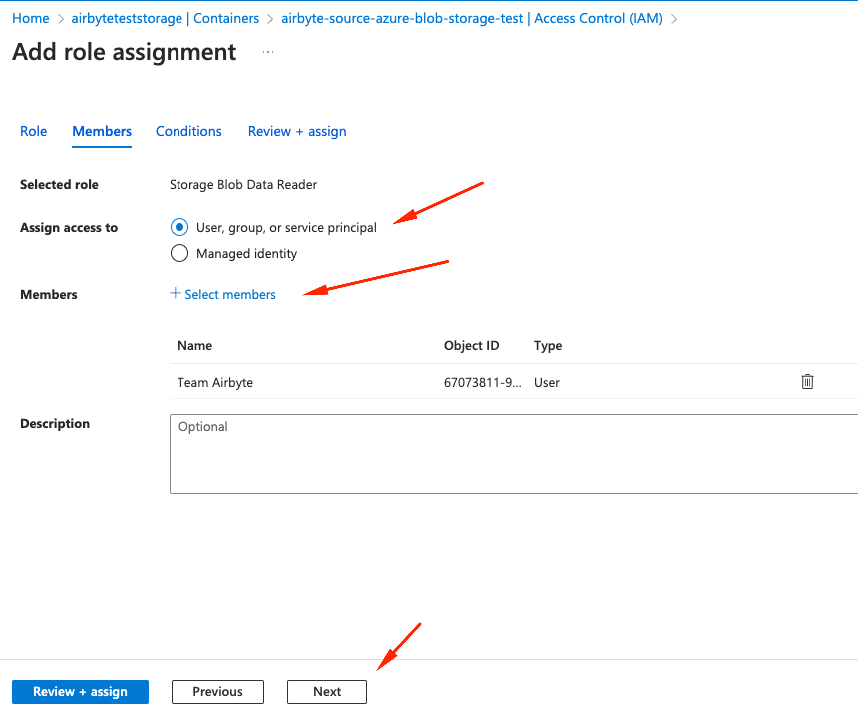
Review + Assign
Follow these steps to set up a Service Principal to use the Client Credentials authentication method.
In the Azure portal, navigate to your Service Principal's App Registration.
Note the Directory (tenant) ID and Application (client) ID in the Overview panel.
In the Manage / Certificates & secrets panel, click Client Secrets and create a new secret. Note the Value of the secret.
Step 2: Set up the Azure Blob Storage connector in Airbyte
For Airbyte Cloud:
- Log into your Airbyte Cloud account.
- Click Sources and then click + New source.
- On the Set up the source page, select Azure Blob Storage from the Source type dropdown.
- Enter a name for the Azure Blob Storage connector.
- Choose a delivery method for your data.
- Enter the name of your Azure Account.
- Enter your Tenant ID and Click Authenticate your Azure Blob Storage account.
- Log in and authorize the Azure Blob Storage account.
- Enter the name of the Container containing your files to replicate.
- Add a stream
- Write the File Type
- In the Format box, use the dropdown menu to select the format of the files you'd like to replicate. The supported formats are CSV, Parquet, Avro and JSONL. Toggling the Optional fields button within the Format box will allow you to enter additional configurations based on the selected format. For a detailed breakdown of these settings, refer to the File Format section below.
- Give a Name to the stream
- (Optional)—If you want to enforce a specific schema, you can enter a Input schema. By default, this value is set to
{}and will automatically infer the schema from the file(s) you are replicating. For details on providing a custom schema, refer to the User Schema section. - Optionally, enter the Globs which dictates which files to be synced. This is a regular expression that allows Airbyte to pattern match the specific files to replicate. If you are replicating all the files within your bucket, use
**as the pattern. For more precise pattern matching options, refer to the Path Patterns section below. - (Optional) Enter the endpoint to use for the data replication.
- (Optional) Enter the desired start date from which to begin replicating data.
For Airbyte Open Source:
- Navigate to the Airbyte Open Source dashboard.
- Click Sources and then click + New source.
- On the Set up the source page, select Azure Blob Storage from the Source type dropdown.
- Enter a name for the Azure Blob Storage connector.
- Choose a delivery method for your data.
- Enter the name of your Azure Storage Account and container.
- Choose the Authentication method.
- If you are accessing through a Storage Account Key, choose
Authenticate via Storage Account Keyand enter the key. - If you are accessing through a Service Principal, choose the
Authenticate via Client Credentials. - See above regarding setting IAM role bindings for the Service Principal and getting detail of the app registration
- Enter the
Directory (tenant) IDvalue from app registration in Azure Portal into theTenant IDfield. - Enter the
Application (client) IDfrom Azure Portal into theClient IDfield. Note this is not the secret ID - Enter the Secret
Valuefrom Azure Portal into theClient Secretfield.
- If you are accessing through a Storage Account Key, choose
- Add a stream
- Write the File Type
- In the Format box, use the dropdown menu to select the format of the files you'd like to replicate. The supported formats are CSV, Parquet, Avro and JSONL. Toggling the Optional fields button within the Format box will allow you to enter additional configurations based on the selected format. For a detailed breakdown of these settings, refer to the File Format section below.
- Give a Name to the stream
- (Optional)—If you want to enforce a specific schema, you can enter a Input schema. By default, this value is set to
{}and will automatically infer the schema from the file(s) you are replicating. For details on providing a custom schema, refer to the User Schema section. - Optionally, enter the Globs which dictates which files to be synced. This is a regular expression that allows Airbyte to pattern match the specific files to replicate. If you are replicating all the files within your bucket, use
**as the pattern. For more precise pattern matching options, refer to the Path Patterns section below.
- (Optional) Enter the endpoint to use for the data replication.
- (Optional) Enter the desired start date from which to begin replicating data.
Supported sync modes
The Azure Blob Storage source connector supports the following sync modes:
| Feature | Supported? |
|---|---|
| Full Refresh Sync | Yes |
| Incremental Sync | Yes |
| Replicate Incremental Deletes | No |
| Replicate Multiple Files (pattern matching) | Yes |
| Replicate Multiple Streams (distinct tables) | Yes |
| Namespaces | No |
Supported Streams
File Compressions
| Compression | Supported? |
|---|---|
| Gzip | Yes |
| Zip | No |
| Bzip2 | Yes |
| Lzma | No |
| Xz | No |
| Snappy | No |
Please let us know any specific compressions you'd like to see support for next!
Path Patterns
(tl;dr -> path pattern syntax using wcmatch.glob. GLOBSTAR and SPLIT flags are enabled.)
This connector can sync multiple files by using glob-style patterns, rather than requiring a specific path for every file. This enables:
- Referencing many files with just one pattern, e.g.
**would indicate every file in the bucket. - Referencing future files that don't exist yet (and therefore don't have a specific path).
You must provide a path pattern. You can also provide many patterns split with | for more complex directory layouts.
Each path pattern is a reference from the root of the bucket, so don't include the bucket name in the pattern(s).
Some example patterns:
**: match everything.**/*.csv: match all files with specific extension.myFolder/**/*.csv: match all csv files anywhere under myFolder.*/**: match everything at least one folder deep.*/*/*/**: match everything at least three folders deep.**/file.*|**/file: match every file called "file" with any extension (or no extension).x/*/y/*: match all files that sit in folder x -> any folder -> folder y.**/prefix*.csv: match all csv files with specific prefix.**/prefix*.parquet: match all parquet files with specific prefix.
Let's look at a specific example, matching the following bucket layout:
myBucket
-> log_files
-> some_table_files
-> part1.csv
-> part2.csv
-> images
-> more_table_files
-> part3.csv
-> extras
-> misc
-> another_part1.csv
We want to pick up part1.csv, part2.csv and part3.csv (excluding another_part1.csv for now). We could do this a few different ways:
- We could pick up every csv file called "partX" with the single pattern
**/part*.csv. - To be a bit more robust, we could use the dual pattern
some_table_files/*.csv|more_table_files/*.csvto pick up relevant files only from those exact folders. - We could achieve the above in a single pattern by using the pattern
*table_files/*.csv. This could however cause problems in the future if new unexpected folders started being created. - We can also recursively wildcard, so adding the pattern
extras/**/*.csvwould pick up any csv files nested in folders below "extras", such as "extras/misc/another_part1.csv".
As you can probably tell, there are many ways to achieve the same goal with path patterns. We recommend using a pattern that ensures clarity and is robust against future additions to the directory structure.
User Schema
Providing a schema allows for more control over the output of this stream. Without a provided schema, columns and datatypes will be inferred from the first created file in the bucket matching your path pattern and suffix. This will probably be fine in most cases but there may be situations you want to enforce a schema instead, e.g.:
- You only care about a specific known subset of the columns. The other columns would all still be included, but packed into the
_ab_additional_propertiesmap. - Your initial dataset is quite small (in terms of number of records), and you think the automatic type inference from this sample might not be representative of the data in the future.
- You want to purposely define types for every column.
- You know the names of columns that will be added to future data and want to include these in the core schema as columns rather than have them appear in the
_ab_additional_propertiesmap.
Or any other reason! The schema must be provided as valid JSON as a map of {"column": "datatype"} where each datatype is one of:
- string
- number
- integer
- object
- array
- boolean
- null
For example:
{"id": "integer", "location": "string", "longitude": "number", "latitude": "number"}{"username": "string", "friends": "array", "information": "object"}
File Format Settings
CSV
Since CSV files are effectively plain text, providing specific reader options is often required for correct parsing of the files. These settings are applied when a CSV is created or exported so please ensure that this process happens consistently over time.
- Header Definition: How headers will be defined.
User Providedassumes the CSV does not have a header row and uses the headers provided andAutogeneratedassumes the CSV does not have a header row and the CDK will generate headers using forf{i}whereiis the index starting from 0. Else, the default behavior is to use the header from the CSV file. If a user wants to autogenerate or provide column names for a CSV having headers, they can set a value for the "Skip rows before header" option to ignore the header row. - Delimiter: Even though CSV is an acronym for Comma Separated Values, it is used more generally as a term for flat file data that may or may not be comma separated. The delimiter field lets you specify which character acts as the separator. To use tab-delimiters, you can set this value to
\t. By default, this value is set to,. - Double Quote: This option determines whether two quotes in a quoted CSV value denote a single quote in the data. Set to True by default.
- Encoding: Some data may use a different character set (typically when different alphabets are involved). See the list of allowable encodings here. By default, this is set to
utf8. - Escape Character: An escape character can be used to prefix a reserved character and ensure correct parsing. A commonly used character is the backslash (
\). For example, given the following data:
Product,Description,Price
Jeans,"Navy Blue, Bootcut, 34\"",49.99
The backslash (\) is used directly before the second double quote (") to indicate that it is not the closing quote for the field, but rather a literal double quote character that should be included in the value (in this example, denoting the size of the jeans in inches: 34" ).
Leaving this field blank (default option) will disallow escaping.
- False Values: A set of case-sensitive strings that should be interpreted as false values.
- Null Values: A set of case-sensitive strings that should be interpreted as null values. For example, if the value 'NA' should be interpreted as null, enter 'NA' in this field.
- Quote Character: In some cases, data values may contain instances of reserved characters (like a comma, if that's the delimiter). CSVs can handle this by wrapping a value in defined quote characters so that on read it can parse it correctly. By default, this is set to
". - Skip Rows After Header: The number of rows to skip after the header row.
- Skip Rows Before Header: The number of rows to skip before the header row.
- Strings Can Be Null: Whether strings can be interpreted as null values. If true, strings that match the null_values set will be interpreted as null. If false, strings that match the null_values set will be interpreted as the string itself.
- True Values: A set of case-sensitive strings that should be interpreted as true values.
Parquet
Apache Parquet is a column-oriented data storage format of the Apache Hadoop ecosystem. It provides efficient data compression and encoding schemes with enhanced performance to handle complex data in bulk. At the moment, partitioned parquet datasets are unsupported. The following settings are available:
- Convert Decimal Fields to Floats: Whether to convert decimal fields to floats. There is a loss of precision when converting decimals to floats, so this is not recommended.
Avro
The Avro parser uses the Fastavro library. The following settings are available:
- Convert Double Fields to Strings: Whether to convert double fields to strings. This is recommended if you have decimal numbers with a high degree of precision because there can be a loss precision when handling floating point numbers.
JSONL
There are currently no options for JSONL parsing.
Document File Type Format
The Document File Type Format is a special format that allows you to extract text from Markdown, TXT, PDF, Word and Powerpoint documents. If selected, the connector will extract text from the documents and output it as a single field named content. The document_key field will hold a unique identifier for the processed file which can be used as a primary key. The content of the document will contain markdown formatting converted from the original file format. Each file matching the defined glob pattern needs to either be a markdown (md), PDF (pdf), Word (docx) or Powerpoint (.pptx) file.
One record will be emitted for each document. Keep in mind that large files can emit large records that might not fit into every destination as each destination has different limitations for string fields.
Parsing via Unstructured.io Python Library
This connector utilizes the open source Unstructured library to perform OCR and text extraction from PDFs and MS Word files, as well as from embedded tables and images. You can read more about the parsing logic in the Unstructured docs and you can learn about other Unstructured tools and services at www.unstructured.io.
Performance considerations
The Azure Blob Storage connector should not encounter any Microsoft API limitations under normal usage.
Copy raw files limitations
When using the Copy raw files delivery method:
- Maximum file size: 1.5 GB per file
- Requires Airbyte version 1.2.0 or later (1.7.0+ for metadata support)
- Only works with file-based destinations that support file transfer
IP allow list
If you use Airbyte Cloud and your organization restricts access to specific IPs, add the Airbyte Cloud IP addresses to your allow list.
Reference
Config fields reference
Changelog
Expand to review
| Version | Date | Pull Request | Subject |
|---|---|---|---|
| 0.8.24 | 2026-07-14 | 81715 | Update dependencies |
| 0.8.23 | 2026-07-07 | 81437 | Update dependencies |
| 0.8.22 | 2026-06-30 | 80986 | Update dependencies |
| 0.8.21 | 2026-06-23 | 80365 | Update dependencies |
| 0.8.20 | 2026-06-16 | 79773 | Update dependencies |
| 0.8.19 | 2026-06-09 | 79224 | Update dependencies |
| 0.8.18 | 2026-06-02 | 78559 | Update dependencies |
| 0.8.17 | 2026-04-28 | 77147 | Update dependencies |
| 0.8.16 | 2026-04-21 | 75028 | Update dependencies |
| 0.8.15 | 2026-03-10 | 74507 | Update dependencies |
| 0.8.14 | 2026-03-03 | 74178 | Update dependencies |
| 0.8.13 | 2026-02-17 | 73438 | Update dependencies |
| 0.8.12 | 2026-01-27 | 72368 | Update dependencies |
| 0.8.11 | 2026-01-20 | 71921 | Update dependencies |
| 0.8.10 | 2026-01-14 | 71450 | Update dependencies |
| 0.8.9 | 2026-01-07 | 71000 | Enable 'Copy raw files' delivery method for file transfers |
| 0.8.8 | 2025-12-18 | 70804 | Update dependencies |
| 0.8.7 | 2025-12-03 | 70316 | Increase memory for check_connection to 4096Mi |
| 0.8.6 | 2025-12-02 | 70291 | Update dependencies |
| 0.8.5 | 2025-11-25 | 69910 | Update dependencies |
| 0.8.4 | 2025-11-18 | 69579 | Update dependencies |
| 0.8.3 | 2025-11-11 | 69269 | Update dependencies |
| 0.8.2 | 2025-11-04 | 69156 | Update dependencies |
| 0.8.1 | 2025-10-29 | 68376 | Update dependencies |
| 0.8.0 | 2025-10-27 | 68615 | Update dependencies |
| 0.7.0 | 2025-10-27 | 68663 | Promoting release candidate 0.7.0-rc.1 to a main version. |
| 0.7.0-rc.1 | 2025-10-21 | 68161 | Update to airbyte-cdk ^v7 |
| 0.6.16 | 2025-10-14 | 68015 | Update dependencies |
| 0.6.15 | 2025-10-07 | 67171 | Update dependencies |
| 0.6.14 | 2025-09-30 | 66167 | Update dependencies |
| 0.6.13 | 2025-08-23 | 65326 | Update dependencies |
| 0.6.12 | 2025-07-26 | 63800 | Update dependencies |
| 0.6.11 | 2025-07-19 | 63472 | Update dependencies |
| 0.6.10 | 2025-07-12 | 63067 | Update dependencies |
| 0.6.9 | 2025-07-05 | 62534 | Update dependencies |
| 0.6.8 | 2025-05-27 | 60867 | Update dependencies |
| 0.6.7 | 2025-05-24 | 60675 | Update dependencies |
| 0.6.6 | 2025-05-10 | 59806 | Update dependencies |
| 0.6.5 | 2025-05-03 | 59318 | Update dependencies |
| 0.6.4 | 2025-04-26 | 58728 | Update dependencies |
| 0.6.3 | 2025-04-19 | 58295 | Update dependencies |
| 0.6.2 | 2025-04-12 | 57627 | Update dependencies |
| 0.6.1 | 2025-04-05 | 43869 | Update dependencies |
| 0.6.0 | 2025-03-31 | 56466 | Upgrading dependencies and CDK and Python to 3.11 |
| 0.5.0 | 2025-01-02 | 50398 | Add client_credentials auth for Azure Service Principals |
| 0.4.4 | 2024-06-06 | 39275 | [autopull] Upgrade base image to v1.2.2 |
| 0.4.3 | 2024-05-29 | 38701 | Avoid error on empty stream when running discover |
| 0.4.2 | 2024-04-23 | 37504 | Update specification |
| 0.4.1 | 2024-04-22 | 37467 | Fix start date filter |
| 0.4.0 | 2024-04-05 | 36825 | Add oauth 2.0 support |
| 0.3.6 | 2024-04-03 | 36542 | Use Latest CDK; add integration tests |
| 0.3.5 | 2024-03-26 | 36487 | Manage dependencies with Poetry. |
| 0.3.4 | 2024-02-06 | 34936 | Bump CDK version to avoid missing SyncMode errors |
| 0.3.3 | 2024-01-30 | 34681 | Unpin CDK version to make compatible with the Concurrent CDK |
| 0.3.2 | 2024-01-30 | 34661 | Pin CDK version until upgrade for compatibility with the Concurrent CDK |
| 0.3.1 | 2024-01-10 | 34084 | Fix bug for running check with document file format |
| 0.3.0 | 2023-12-14 | 33411 | Bump CDK version to auto-set primary key for document file streams and support raw txt files |
| 0.2.5 | 2023-12-06 | 33187 | Bump CDK version to hide source-defined primary key |
| 0.2.4 | 2023-11-16 | 32608 | Improve document file type parser |
| 0.2.3 | 2023-11-13 | 32357 | Improve spec schema |
| 0.2.2 | 2023-10-30 | 31904 | Update CDK to support document file types |
| 0.2.1 | 2023-10-18 | 31543 | Base image migration: remove Dockerfile and use the python-connector-base image |
| 0.2.0 | 2023-10-10 | 31336 | Migrate to File-based CDK. Add support of CSV, Parquet and Avro files |
| 0.1.0 | 2023-02-17 | 23222 | Initial release with full-refresh and incremental sync with JSONL files |